


This document is the reference documentation of TinyWorkflow.
This document presents all aspects of TinyWorkflow in a systematic way.
If you need an introduction or overview of TinyWorkflow, it's better to read the following document first:
The WorkflowXmlReference.html document is a complete description of the XML syntax of a workflow definition.
TinyWorkflow is organized in several components:
You can have more info about these component by browsing their specific documentaion (under modules if the left menu)
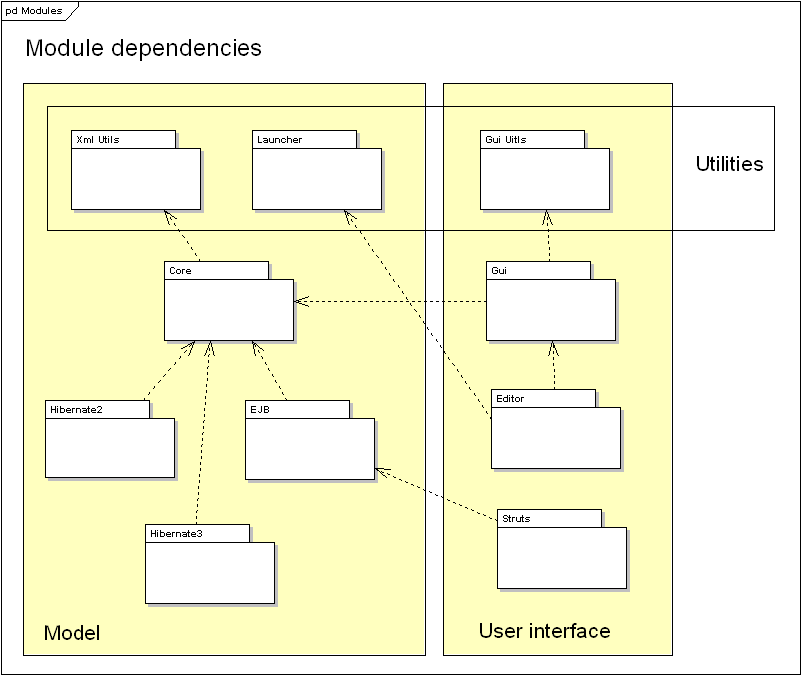
Dependencies shown in this diagram are transitivies.
To use TinyWorkflow, you have to use the TinyWorkflow-Core project and one persitency implementation (note: the default in-memory persitency is bundled in the core project). All other components are optional.
Note:
TinyWorkflow Core and XmlUtils require:
For other components, see the specific dependency list of those components in their documentation.
For a typical usage of the TinyWorkflow engine with Hibernate3 persitence you need to have the following jars in your classpath:
The TinyWorkflow components:
The dependencies of the core
The dependencies of Hibernate3
When you download TinyWorkflow you got an archive (zip, tgz) containing the following files:
TinyWorkflow comes with a set of examples.
TODO.
TinyWorkflow is build with Maven 2 (http://maven.apache.org/). It uses regular maven 2 project structure, so to build it, just install the latest Maven version and follow maven build instructions.
Each TinyWorkflow component is a maven project and all the projects are grouped as modules of the TinyWorkflow project. The TinyWorkflow project's POM is the parent for the POMs of each module. So, if you want to build everything in one command, go to the TinyWorkflow directory and type
mvn package
Note: the site generation plugin of Maven 2 is not (yet) completely OK, so the generation of this site requires some manual interventions. TODO: describe.
The definition XML file encodes the workflow state machine as explained in the GettingStarted.html.
The workflow definition is composed of:
The workflow definition is a transcription of a Finite State Machine. The <workflow> tag is the root tag of the declaration. A workflow definition is uniquely identified by the workflow definition id (the 'id' attribute).
In addition to the id, a workflow definition is identified by its version number. If you modify a workflow definition, it's better to increase the version number (especially if you remove states or transitions or if you modify state/transition ids).
The version number can be any String. You just have to ensure that they are correctly ordered: when a version is greater than another, the version number of this version must be greater than the other version number (when compared using the standard string comparison). Using the 'dotted notation' ('1.0.0', '1.0.1', '1.1') fit this requirement as long as you always use the same number of digits. Counterexample: '1.9.5' > '1.10.4' when you use string comparison. If you have this problem, one simple solution is to use letters (like in hexadecimal): '1.9.5' < '1.A.4'.
When you create a workflow, you can specify null as version number. In this case, the latest workflow definition version available in the repository is used. It's a good practice to always do that.
When an instance of the workflow is loaded and the repository contains a newer version of the workflow definition, the workflow is 'upgraded' to use the new workflow definition (the version id of the current workflow definition if upgraded). This upgrade is visible in the history in the form of an 'upgrade' transition. The automatic upgrade can be disabled on the WorkflowDefinitionRepository by calling setAutoUpgrade(false).
In a future version of TinyWorkflow this 'upgrade' transition will also change the workflow state when the current state of a workflow instance no more exists.
Note that the exact version of the workflow definition used to for states and transitions is kept in the workflow history. So, even if a transition or state disappeared from a workflow definition, it can be found back in the correct older versions.
Many definition objects (WorkflowDefinitions, StateDefinitions, TransitionDefinitions ...) are identified by an ID. This ID is internal and should not be displayed to the user. It is used by the workflow engine to identify objects.
In addition to the ID you can define a Name and descriptions. The name and description are Strings to be displayed to the user. They are not used by the workflow engine. Doing a clear separation between Name and ID helps maintenance as the name can change but the ID should stay the same (for backward compatibility). Of course, name and description are not mandatory. They are there to improve readability of the definition or to support user interface construction. If you don't need them, just ignore them.
If your application must support multiple languages, then you can provide names and description in multiple languages. This is done like usual localisation in java. The languages are identified by a locale. The usual locale matching algorithm of java is used to find the name/description in a given locale. For example, if the user locale is "fr_BE" it will check for:
Note: When you have to provide names/descriptions in several languages. It's recommended to alaways define a default one (without locale) that will be used for all locales not matching the proposed one.
Name and Description elements are declared in XML and used in java exactly the same way.
You can define, for example, names of some states as following:
<state id="someState1" name="Some State">
...
</state>
<state id="someState2">
<name value="Some state" />
...
</state>
<state id="someState3">
<name value="Some state" />
<name locale="fr" value="Un état" />
</state>
<state id="someState4">
<name>Some state</name>
<name locale="fr">Un état</name>
</state>
<state id="someState5" name="Some State" >
<description>
Some very long description
of my state
using multiple lines.
</description>
</state>
in this example:
In your java code, you can get the name or description from the workflow definition objects (workflowDefinition, transitionDefinitions ...).
// Display the name of the current workflow state
Workflow wf = ...
Locale loc = ...
StateDefinition stateDef = wf.getCurrentStateDefinition();
System.out.println("The current state is: " + stateDef.getName(loc));
A basic inheritance mechanism is defined for workflow definitions.
A workflow definition can declare that it extends other workflows.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<workflow xmlns="http://org.tinyWorkflow/2005/WorkflowDefinition" id="extensionTest" version="1.0">
<extends id="someWorkflow" version="1.0"/>
...
This simply means that all initial transitions, global transitions and states defined in the parent workflow are available in the extended workflow (just as if they were declared in this workflow). If some global/initial transition or state of the child workflow has the same ID as one of the parent one, it simply overrides the definition of the parent.
When you extends multiple workflows redundant definitions are ignored.
In some worklfow definition objects, you can add meta-data (WorkflowDefinition, StateDefinition, TransitionDefinition, parameterDefinition ...). This data is not used by the workflow engine. It's just available in the definition for use by other code.
For example, if your application generate user interface based on the workflow definition then meta-data can be a good place to put some useful information. Let's say you want to show a toolbar displaying all the transitions that can be executed by the current user on a worklfow. You can put in each transition meta-data giving the name of the icon to set in the toolbar button.
Meta-data can be customized: you can define your own meta-data object and use them in your worklfow definition. See Customisation.html for more info.
Meta-data are identified by an ID and have a value that can be nay Object. They are always defined between <meta> ... </meta> tags. There are two meta-data pre-defined in TinyWorkflow:
Examples:
...
<globalTransitions>
<transition id="t1">
<meta>
<property id="icon" value="MyIcon.png"/>
<nameData id="name">
<name value="John"/>
<name locale="fr" value="Jean"/>
</nameData>
<textData id="text">
<text>
Hello
Everybody
</text>
<text locale="fr">
Bonjour
tout le monde
</text>
</textData>
</meta>
...
You can access the meta-data defined in this example like this:
// Get some meta-data values from transition "t1" definition
WorkflowDefinition wfDef = ...
Locale loc = ...
TransitionDefinition transDef = wfDef.getGlobalTransitionDefinition("t1");
String iconName = (String) transDef.getMetaData("icon");
System.out.println("The icon to use is: " + iconName);
MultiLingualText text = (MultiLingualText) transDef.getMetaData("text");
System.out.println("The text is: " + text.getText(loc));
The functions are invocation of a piece of code. They are the link between the workflow definition and the java code.
Functions can be of 3 types:
Functions can be customized: you can define your own function object and use them in your worklfow definition. See Customisation.html for more info.
Examples:
<transition id="trans1">
...
<preFunctions>
<beanshellFunction>
String myParam = (String) context.getParam("myParam");
context.getPeer().doSomeAction(myParam);
</beanshellFunction>
<peerCall method="doOtherAction"/>
</preFunctions>
<results>
<result state="state1"/>
</results>
<postFunctions>
<proxyFunction class="org.tinyWorkflow.definition.FakeFunction">
<meta>
<property id="p1" value="val1"/>
<property id="p2" value="val2"/>
</meta>
</proxyFunction>
</postFunctions>
</transition>
The pre-functions are called before the workflow action are executed, and the post-functions are called after. So when you query, for example, the workflow state from a pre-function of a transition getCurrentStateDefinition() give you the state before the transition, in post-functions, it gives you the state after the transition.
Pre and post functions can be defined for Workflow, States and transtions. The most common used place to put functions is the pre-function of the transition. It's the usually the best place to put business logic that must be executed during a transition.
The following table shows when the pre and post fuctions are triggered depending on the container defining them:
| Container | Pre-functions | Post-functions |
| Workflow | Just before the initial transtion is executed. | After the transition leading to the final state. |
| State | Each time the workflow is put in that state (comming from a different one). | When the workflow leave the state. |
| Transtion | Before the transition executed. | After the transition is executed. |
Initial transitions are transitions starting the workflow. Usually, the transitions are defined in their origin state. But, as in TinyWorkflow the initial state of the workflow is not defined as a state, the initial transitions are defined in the special <initialTransitions> section of the workflow definition. See Transition Definition to have details about the content of a transition definition.
Before the initial transition, the current state of the workflow is not defined (getCurrentStateDefinition() == null) and the workflow golbal state is "not started" (getGlobalStatus() == Workflow.STATUS_NOT_STARTED)
It is recommended always directlty execute an intial transition on any newly created workflow. If you use a relational database, it's better to do it in the same database transaction.
In following example, we create a workflow with definition "unitTest1" and directly execute the "init" initial transition on it (in one single database transaction).
WorkflowPersistenceFactory factory = ...
WorkflowDefinitionRepository repo = ...
WorkflowPersistence persistence = factory.createPersistence();
persistence.beginTransaction();
Workflow wf = repo.createWorkflowInstance("unitTest1", null, persistence);
wf.doTransition("init", null, "MyUser");
persistence.commitTransaction();
Global transitions are simply transition definitions that can be reused in any state. See Transition Definition to have details about the content of a transition definition.
When you define a global transition in your workflow like the "lock" transition below:
...
<globalTransitions>
<transition id="lock" name="Lock Workflow">
<conditions>
<workflowHasNoOwner/>
</conditions>
<results>
<result state="${oldStateId}" owner="${callerId}"/>
</results>
</transition>
...
you can reuse it in any state of the workflow (or the in workflows extending it) with a transition reference <transitionRef>:
...
<state id="readyForPublishing">
<transitions>
<transitionRef refId="lock"/>
...
It allows factor out transitions appearing in several states.
When you reference a global transition with <transitionRef> you can override any part of the transition you reference. So the referencing works also as inheritance: you can modify the transition behavior in the reference.
When you override an permissions, conditions, parameters, pre/post functions or results, you override the whole XML element content (the whole list of permission, conditions ...) at once. For those definition, there is no mix possible between what's in the global transition and what's in the transition reference.
On the other hand, for name, description and meta-data it's possible to add something or partially replace the definition done in the parent. It's because those data are accessed with a key (the "locale" for name/description or the "id" for meta-data).
You can, for example, write (reusing global transition defined above):
...
<state id="readyForPublishing">
<transitions>
<transitionRef refId="lock"/>
<name locale="fr" value="Verouiller le flux"/>
<conditions>
<workflowHasNoOwner/>
<allowedCaller ids="Bill,Bob"/>
</conditions>
</transitionRef>
...
In this case, we add a french translation for the name and a condition allowing only Bill and Bob to perform the "lock" transition. Note that, to add a translated name, we just put it in the reference transition. But to add a condition, we had to rewrite the original condition in the new condition list.
When referencing a transition, you can also assign a new ID to it with the 'id' parameter. If no id parameter is specifed, the same id as the global transition is used. By specifiing an ID, you can reference the same global transition twice from a state and override diffrent parts of the global transition in each reference.
example:
...
<state id="readyForPublishing">
<transitions>
<transitionRef refId="lock"/>
<transitionRef refId="lock" id="rootLock" name="Forced lock for root user" />
<conditions>
<allowedCaller ids="Root"/>
</conditions>
</transitionRef>
...
The first reference just enable the use of the 'lock' transition (as defined in global transitions) in the 'readyForPublishing' state. The other transition references the same global transition with another id ('rootLock') assigned (because two transitions of the same state cannot have the same ID). In this second transition the conditions are overriden to allow the 'Root' user to bypass the the 'workflowHasNoOwner' condition of the global transition.
The state definition is definition of a state of the state "machine". It is identified by a unique ID (given as a mandatory XML attribute of the <transition> element).
States are of two types:
A state definition contains (in this order)
Note: there is no "initial state" representation in TinyWorkflow. It's because they have no name, descrition, functions or meta-data. The transitions virtually starting from the "initial state" are the initial transitions.
Each state contains the list of all transition starting from itself. They are declared in the <transitions> XML element.
The transitions in the state can be of two types:
The transition definition is definition of a transition of the "state machine". It is identified by a unique ID (given as a mandatory XML attribute of the <transition> element).
The transition can define an 'auto' attribute to enable automatic transitions (see Automatic Transitions).
Each transition definition is composed of (in this order):
The execution of a transition can return a Map of values (see Return Values).
Inside some XML attributes of transition definitions you can define expression of the form ${expression}. See Beanutils expressions for more info and WorkflowXmlReference.html to find which parameters allow to define expressions.
An automatic transition is a transition defined with the XML parameter auto='true'.
After a transition is done, the workflow checks all the automatic transitions of the current workflow state. If it finds a transition for witch permissions and conditions are met, the transition is performed automatically.
The caller id of the transition is set to Workflow.SYSTEM_USER_ID and the given map of parameters is null. This check for automatic transition is performed repeatedly until there is no such transition available.
If a parent workflow exists, the automatic transitions of the parent are also triggered.
The automatic transitions can be triggered just bay calling the doAutomaticTransitions() on the workflow. In this case, the all the available automatic transition of the workflow (and possible parent workflows) are performed just as after a transition.
The fact that the automatic transitions are automatically executed after any transition can be disabled. Just put the special parameter Workflow.AUTO_TRANSITION_PARAM with value Boolean.FALSE in the map of parameter of a transition.
It allows controlling yourself when the automatic transitions are performed.
This is useful, for example, if you want that the main transition and the possible automatic transitions following it are executed in different Database transactions.
Just do something like:
...
Workflow wf = ...
Map input= ...
// disable the automatic transition by putting a special parameter in the input Map
inputs.put(Workflow.AUTO_TRANSITION_PARAM, Boolean.FALSE);
// do the transition in one DB transaction
startTransaction();
wf.doTransition("someTransition", inputs, "Billy");
commitTransaction();
// trigger the automatic transitions in a separate DB transaction
startTransaction();
wf.doAutomaticTransitions();
commitTransaction();
...
In attributes of some XML element you can put expressions in the form of ${expression}. The expression used here is an Apache/Jakarta Commons-BeanUtils expression (http://jakarta.apache.org/commons/beanutils).
Those expressions are evaluated at runtime when the transition is performed. They are relative to the current TransitionContext (of type org.tinyWorkflow.instance.TransitionContext).
Basically this API maps 'attributes' of the expression to java methods like following:
| Expression | Mapped code |
| ${someAttribute} | context.getSomeAttribute() |
| ${mappedAttr(key)} | context.getMappedAttr("key") |
| ${indexedAttr[i]} | context.getIndexedAttr(i) |
You can combine expression with dots:
| Expression | Mapped code |
| ${someAttribute.mappedAttr(key).indexedAttr[i]} | context.getSomeAttribute().getMappedAttr("key").getIndexedAttr(i) |
Here is a list most commonly used expressions:
| Expression | Mapped code | Description |
| ${oldStateId} | context.getOldStateId() | The Id of the workflow state before the transition. It's useful for defining self transitions. |
| ${oldOwnerId} | context.getOldOwnerId() | The Id of the owner of workflow state before the transition. |
| ${callerId} | context.getCallerId() | The Id of the user executing the transition. |
| ${param(paramId)} | context.getParam("paramId") | Get a parameter of the transition. |
| ${workflow} | context.getWorkflow() | Get the workflow instance. |
| ${peer} | context.getPeer() | Get the workflow peer. |
The expressions are mostly used inside <expressionEquals> conditions or in attributes of transition results.
You can put several expressions inside a single attribute like, in this case they are transformed to string and concatenated.
...
<results>
<result state="${oldStateId}" logInfo="Setting value from ${param(oldMyParam)) to ${param(myParam)}"/>
</results>
...
Where "myParam" is a parameter of the function, and "oldMyParam" has been put in the transition context in some pre-function.
The <parameters> element lists the parameters of the transition. Parameter definitions are used to validate the transition input. It's also a way to document the expected parameters and to support GUI building automatic input forms.
A parameter definition usually contains:
The abstract class org.tinyWorkflow.definition.parameter.BaseParameterDefinition gives a base implementation of a parameter definition inmplementing all this usual behavior of the parameter definitions.
Parameter definitions can specify additionl constraints depending of the parameter type (max. length, max. value, enumerations, ...)
Parameters can be customized: you can define your own parameter types and use them in your worklfow definition. See Customisation.html for more info.
Example of defining parameters:
...
<transition id="sample1">
...
<parameters>
<stringParameter id="param1" minLength="1" maxLength="256" defaultValue="enter a value">
<name value="Parameter 1" />
<name locale="fr" value="Paramètre 1" />
</stringParameter>
<booleanParameter id="param2" mandatory="false" />
</parameters>
...
for a complete list of standard parameters definitions with all their attribute description, see WorkflowXmlReference.html
TinyWorkflow defines permissions and conditions. Both are boolean expressions guarding the a transition execution. From the point of view of implementation they are the same: you can move everything you find in <permissions> in <conditions> (and vice-versa) without affecting the workflow behavior. The only diffrence between permission and conditions is the meaning they have:
For the workflow engine, there is no difference: a transition can be executed only if all the permissions and conditions are met.
They are however separated because, usually, the user interface are doing difference between those two. What the user is not permitted to do is not shown to him (because, as it will never be able to perform some transition, he has no need to even know they exists). What can not be executed for temporary conditions is shown but disabled (So the user can see that some transitions will be available if he make the preconditions happening). To support that, TinyWorkflow provides the method getTransitionsAvailability(..). It returns a list of all the transitions defined in the current workflow state with a flag saying if it is available and if the user has the permission to execute them.
If you don't want to implement such a advanced GUI, simply call getAvailableTransitions(..) to have the list of all available transitions (for which both permissions and conditions are met). Then you can choose to use only one of <permissions> or <conditions> elements in XML (or sill use both for declaration clarity).
Both <permissions> and <conditions> contains a list of boolean expressions that must be true (AND combination) for the transition to be allowed. Various pre-defined boolean expressions (simply called 'Conditions' though they can also be used in <permissions>) are provided by TinyWorkflow. For a complete list see WorkflowXmlReference.html
Conditions can be customized: you can define your own condition types and use them in your worklfow definition. See Customisation.html for more info.
Conditions can also be combined with the usual "AND", "OR" and "NOT" operators:
...
<conditions>
<or>
<callerIsWorkflowOwner/>
<and>
<callerIsSystem/>
<paramEquals paramId="myParam" value="abc"/>
</and>
</or>
</conditions>
...
Don't forget that the <conditions> itself act like a <and> condition.
The <results> section of a transition define what will be the state of the workflow after the transition is executed.
The result define:
The result list can define more than one result. In this case the result must be <conditionalResult> XML elements. Thos results have an additional condition allowing the workflow engine to choose what will be the actual result. The last result of the result list is always not conditional because it's the default one that is chossen when all the conditions of the previous results are false.
The conditional result is just like a normal result (same attributes) with a condition inside it. The conditions used here are exactly the same as the one used to guard transition execution (see Permissions and Conditions). Of course, some conditions (like <workflowHasNoOwner>) are not usefull in this context. You will usually check an expression on the current context (using for example <expressionEquals ... >) that have been set during pre-functions to choose what will be the result.
The workflow engine simply evaluate the conditions of the result list in the order they are defined. The first result with a true condition is used.
Example of result list with condituional result:
...
<results>
<conditionalResult state="Processing" owner="${oldOwnerId}">
<or>
<expressionEquals eval="${oldStateId}" value="Valid"/>
<expressionEquals eval="${oldStateId}" value="Invalid"/>
</or>
</conditionalResult>
<result state="${oldStateId}" owner="${oldOwnerId}"/>
</results>
...
This it the result list of a global transition specifying that the transition doesn't change the workflow state except when it comes from the "Valid" or "Invalid" state. In this case the workflow goes in the "Processing" state. The owner of the workflow always stays the same.
Note: you can achive the same by using only the non-conditional result in the global transition and overriding the results in the transition references of the "Valid" and "Invalid" states.
Each workflow can define a current owner. It allows to easily assign workflows to users. This owner is not directly used by the workflow engine (it is just logged in the workflow history) but you can define conditions using it.
Conditions checking the workflow owner are:
Using those conditions, it's easy to define a 'locking' mechanism on the workflow. Just define the following global transitions:
...
<globalTransitions>
<transition id="lock" group="locking">
<conditions>
<workflowHasNoOwner/>
</conditions>
<results>
<result state="${oldStateId}" owner="${callerId}"/>
</results>
</transition>
<transition id="unlock" group="locking">
<conditions>
<callerIsWorkflowOwner/>
</conditions>
<results>
<result state="${oldStateId}"/>
</results>
</transition>
</globalTransitions>
...
Those transitions have as effect to set/reset the workflow owner (without changing the current state).
Then you can reference those transitions from some states and guard the other transition with <callerIsWorkflowOwner/> to allow that only to the current workflow owner perfroms them:
...
<state id="state1">
<transitions>
<transitionRef refId="lock"/>
<transitionRef refId="unlock"/>
<transition id="doSomething">
<conditions>
<callerIsWorkflowOwner/>
</conditions>
...
By setting wisely the result owner of each transition, you can control how the workflow is assigned to users during its lifetime. Doing that, you can eliminate the usual concept of 'Task' (usualy seen in other workflow engines) because you can assign the workflow itself.
A workflow transition execution can return a Map containing useful data.
In the Usual worklow paradigm, the returned Map is null. This is because the workflow is seen as an object on which you execute transitions and the transitions are not meant to be "queries for a result" but action modifying the workflow state. After the transition, the state of the workflow (and its associated peer) can be inspected. This is the regular use of workflow and so, returning values is not encouraged.
However, sometimes it's useful to be able to pass some 'transient' values to the transition caller. Those value have no place in the object model of the workflow because they are related to one specific transition execution.
Typical example is a warning message: the transition was performed correctly but you want to display some warning to the user who performed it. In this case, you cannot put the warning message in the workflow because any other transition call (possibly made by another user) can clear it before you got a chance to display it.
To return a value from transition, just put it in the workflow TransitionContext during the transition:
TransitionContext context = ...
context.setResult("WARNING_MESSAGE", "This is an example of warning");
Then the code calling the transition can get the message from the returned map.
Note: when no result is set on the TransitionContext, the returned Map is null.
Workflow wf = ...
Map results = wf.doTransition("someTransition", null, "Billy");
Object warningMessage = (results == null) ? null : results.get("WARNING_MESSAGE");
if (warningMessage != null) {
// Got a warning from transition execution
System.out.println("Returned value: " + warningMessage);
}
The central class for TinyWorkflow usage is the WorkflowDefinitionRepository. As you guessed, this class is used to hold the workflow definitions.
You can use the repository as a singleton, in this case always get the unique instance by calling:
WorkflowDefinitionRepository repo=WorkflowDefinitionRepository.getInstance();
If you don't want a singleton, you can just create a new WorkflowDefinitionRepository instance.
Once you have a WorkflowDefinitionRepository, you can load the workflow XML definitions in it with the addXmlDefinition(..) method. This method accept a File, a URL or a Stream.
If you have some definitions extending other definitions, you have to load the base definition first and the the extension. Otherwise you will get an exception when the extension try to bind itself to the parent workflow.
Once you have loaded all the workflow definitions you need, you are ready to create workflow instances. The workflow instances share the same workflow definition. As they contain no data related to workflow execution, they are re-entrant and can be shared beween all workflows without any concurrency problem (The definition are not supposed to be modified when running workflows).
The workflow instances are created or loaded using helper methods of the worklfow repository. It's because a workflow instance must always be attached to a workflow definition. The repository does that for you.
To instantiate a workflow just do:
WorkflowDefinitionRepository repo=null;
try {
// Get the respository singleton and add a XML worklfow definition in it.
repo = WorkflowDefinitionRepository.getInstance();
repo.addXmlDefinition(getClass().getResource("doc/sampleDoc.xml"));
} catch(Exception e) {
System.err.println("Unable to configure the workflow repository");
e.printStackTrace();
}
// create a new workflow instance
Workflow myNewInstance = repo.createWorkflowInstance("myDefinition", "1.0");
Object instanceId = myNewInstance.getId();
To get back (load) a workflow that was previously persisted (saved in database) you also have to use the WorkflowDefinitionRepository. The workflow are identified by a unique id (a database key), just give the key to the WorkflowDefinitionRepository and it will give you back your workflow. The workflow id can be obtained with the getId() method. The id itself is generated by the persistence layer.
Just do:
WorkflowDefinitionRepository repo = ...
Object instanceId = ...
// get back a previously saved workflow instance
Workflow loadedInstance = repo.getWorkflowInstance(instanceId);
The workflow repository get the workflow from the persistence layer. It checks the workflow definition id and version of the loaded workflow and it attach the correct definition to it. The definition used by the loadaed workflow must be present in the repository.
Note: in these examples we did not configure the WorkflowPersistence, so it uses the default MemoryPersistence. See the Workflow Persistence chapter for more info.
When you have a workflow instance, just call the "doTransition" method to execute a transition.
This method takes 3 parameters:
The first thing don by TinyWorkflow when a transition is started is to build a TransitionContext. The transitionContext is an object gathering all the information available at this time. It will be passed to all objects participating to the transition execution (permissions, conditions, functions ...).
In particular, if you give a Principal object to the doTransition method, it is stored as such (and made accessible) in the principal. It allows you to give your own principal class (or a standard java security class implementing principal) and implement your own permissions based on the information availble in this principal.
The transition is executed as following:
It is possible to check what are the actions that can be executed by one user on a workflow. Just call the getAvailableTransitions(..) method to have the list of the transitions fullfilling the permissions and conditions (for a specific user)
In the following example, we print all the transition of the workflow 'wf' available for a user. For each available transition, the transition id and all the transition parameters are printed.
Workflow wf = ...
String userId = ...
System.out.print(" > Available transitions for " + userId + " are:");
List transitions = wf.getAvailableTransitions(null, userId);
for (Iterator it = transitions.iterator(); it.hasNext();) {
TransitionDefinition trans = (TransitionDefinition) it.next();
System.out.print(" ");
System.out.print(trans.getId());
// display parameters of the transition
Iterator params = trans.getParameterDefinitions();
if (params.hasNext()) {
System.out.print("(");
for (; params.hasNext();) {
TransitionParameterDefinition param = (TransitionParameterDefinition) params.next();
System.out.print(param.getId());
if (params.hasNext()) System.out.print(",");
}
System.out.print(")");
}
}
System.out.println("");
Note: we usually pass null instead of the parameter Map to the getAvailableTransitions(..) method. This is because the conditions and permissions rarely depends of the parameters. But it's possible to put such conditions (for example with <paramIsDefined> condition). In this case, you have to give the parameters to have a correct evaluation of the conditions.
If you want to make a difference between permissions and conditions, you have to call the getTransitionsAvailability(..) method. It will return you a list of TransitionAvailability objects on which you can check if the permissions are OK and/or if the conditions are OK.
The workflow data (the set of all the instance data of the workflow) can be seen as 'primary data' and 'aggregated data'.
The aggregated data is there to help usage of the workflow by giving meaningful information 'aggregated' from the workflow history. So the user can simply access this information, there's no need to re-calculate it at each access. Another advantage of the aggregated data is that this data is saved in the database (when you use database persistence); this allows performing workflow selection based on this aggregated data.
The aggregated data contains:
When watching a list of workflows in an application, the user usually wants some specific information about the workflow in addition to the current state. For example: "Did the workflow ever go to a specific state ?", "does the workflow have active sub-workflows ?", "Does the workflow have a child workflow in some specific state ?", "Does the workflow peer contain some specific object ?". To answer to those questions, you need to perform a complex check (like scanning the history or evaluating the state of each sub-workflow). This is too heavy to do when listing the workflows, so the solution is to calculate those flag each time the workflow is modified and store it in a generic way. Then we can retrieve it with a simple select and display those flags values in workflow lists.
Let's look, for example, at the subWorkflowFlag.
This flag has a boolean value. It is true when the workflow has child workflows defined.
If you define the following flag list in the workflow XML definition:
...
<flags>
<subWorkflowFlag id="activeChildren" mask="1" noSub="None" someSub="Some"/>
</flags>
...
It means that you define a flag with id="activeSubCount" and value "None" when there is no active child workflow or value "Some" when there are active child workflows.
When this flag is defined you can query it value at any moment from the workflow:
myWorkflow.getFlagValue("activeChildren");
All the flag values are encoded in a single int value. It's the reason why they can only have enumerated values. The mask attribute gives the bits where the flag values are encoded inside the int. You can retrieve the int encoding the flags (directly from the database or using the getFlagsIntValue() method) and deduce all the flags values by using the FlagList object of the workflow definition.
You can create your custom flag objects with the standard extension mechanism provided by TinyWorkflow: see Customisation.html for more information.
TinyWorkflow uses a set of interface to manage interactions with the storage backend (the database). This set of interface is called the 'persistence'. Several implementations of the persistence interfaces are provided:
The memory persistence is a simple implementation of the persistence interface of the workflow. This persistence only keeps everything in memory.
This persistence is useful only for tests and demos.
The Hibernate persistence simply provide concrete classes for the TinyWorkflow abstract implementation and maps them to database tables.
| Abstract Class from org.tinyWorkflow.instance | Concrete Class from org.tinyWorkflow.persistence.hibernate | Database Table |
| Workflow | HibernateWorkflow | WF_INSTANCE |
| WorkflowHistoryTransition | HibernateWorkflowHistoryTransition | WF_HIST_TRANS |
| WorkflowHistoryState | HibernateWorkflowHistoryState | WF_HIST_STATE |
The are two Hibernate persistence available one using Hibernate 2.x and one using the new 3.x version. To have more information about those persistences, go to the documentation of the Hibernate2 / Hibernate3 modules.
The WorkflowPersistenceFactory adds another degree of abstraction in persistence management. This factory simply provides a method to create WorkflowPersistence instances. It allows to write code independent from the persistence implementation.
You can set such a factory on the WorkflowDefinitionRepository, so it can create persistence itself when it loads/creates workflows. The drawback of this 'automated' usage of persistence is that you have less control on database transaction management. In particular, TinyWorkflow-Core classes never begin/commit/rollback transactions.
TODO.